Abstract
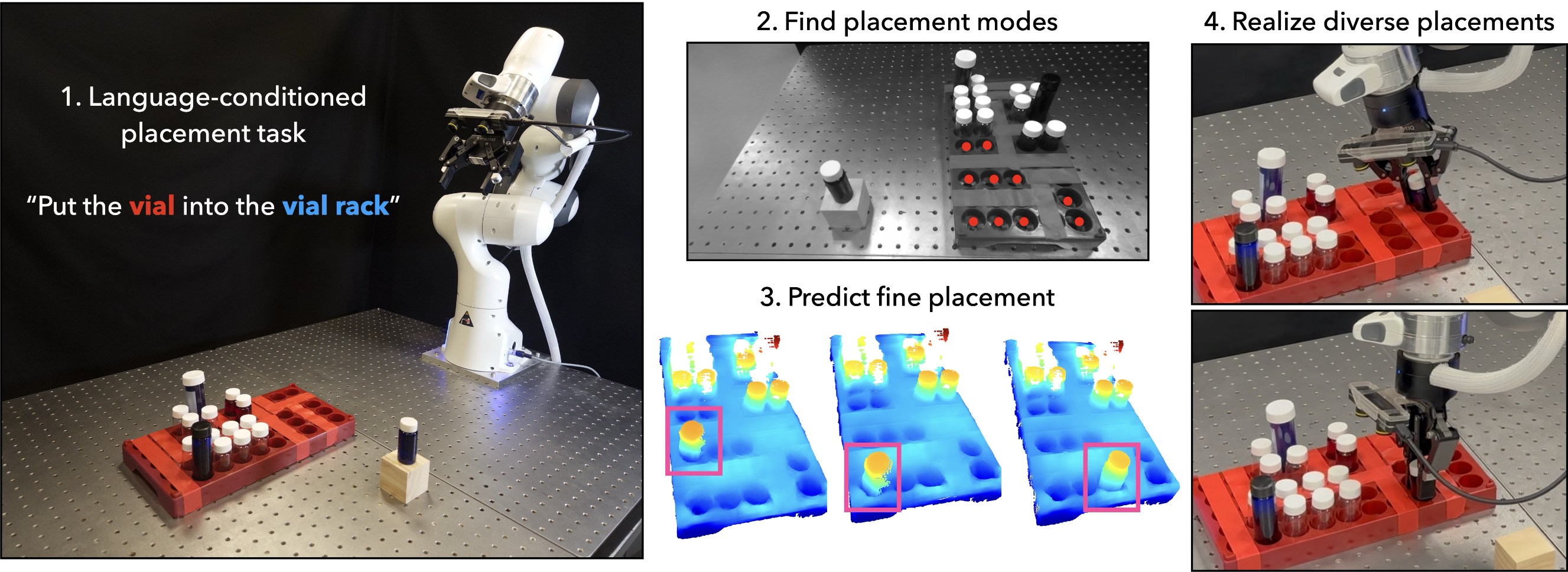
Achieving robust and generalizable object placement in robotic tasks is challenging due to the diversity of object geometries and placement configurations.
To address this, we propose AnyPlace, a two-stage method trained entirely on synthetic data, capable of predicting a wide range of feasible placement poses for real-world tasks. Our key insight is that by leveraging a Vision-Language Model (VLM) to identify rough placement locations, we focus only on the relevant regions for local placement, which enables us to train the low-level placement-pose-prediction model to capture diverse placements efficiently. For training, we generate a fully synthetic dataset of randomly generated objects in different placement configurations (insertion, stacking, hanging) and train local placement-prediction models.
We conduct extensive evaluations in simulation, demonstrating that our method outperforms baselines in terms of success rate, coverage of possible placement modes, and precision. In real-world experiments, we show how our approach directly transfers models trained purely on synthetic data to the real world, where it successfully performs placements in scenarios where other models struggle -- such as with varying object geometries, diverse placement modes, and achieving high precision for fine placement.
AnyPlace Prediction Pipeline
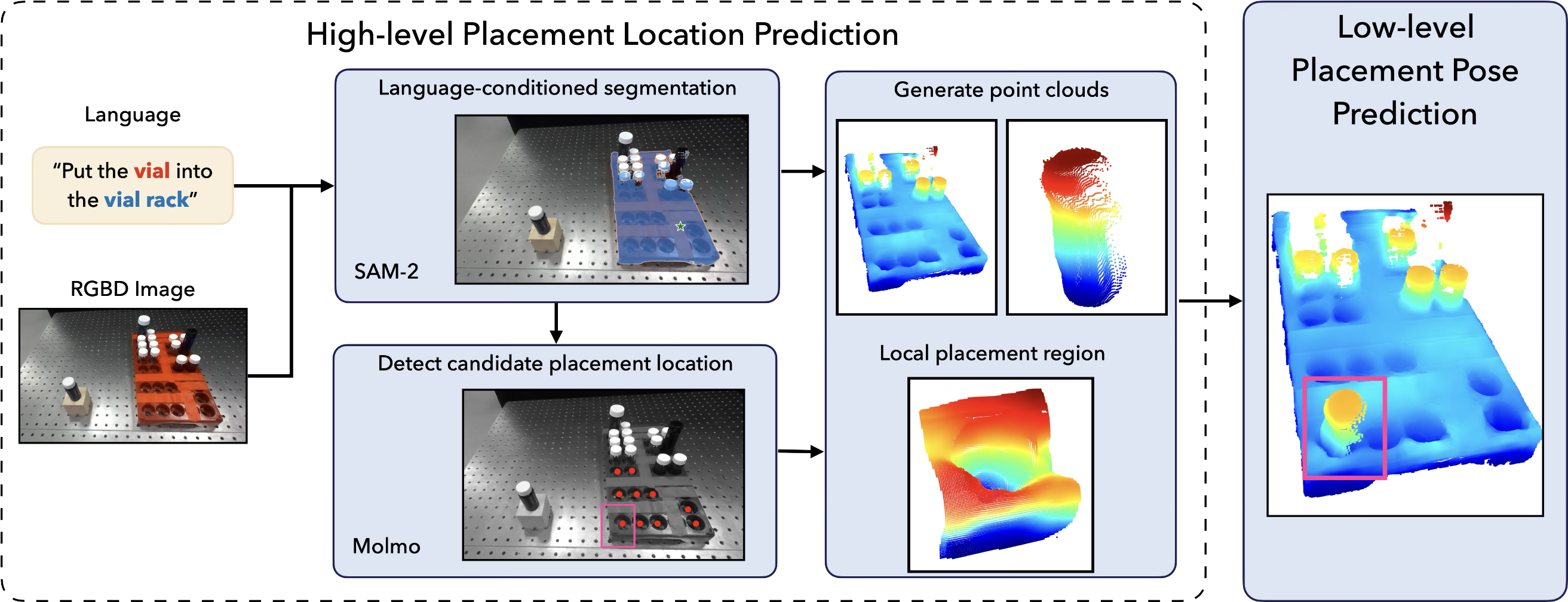
Our AnyPlace pipeline consists of two stages: high-level placement position prediction and low-level pose prediction. For high-level placement position prediction, given an input language description and an RGBD image, we leverage Molmo and SAM-2 to segment objects of interest. Next, we prompt Molmo again to propose possible placement locations. Using camera parameters, we reproject the depth map into 3D and crop the region of interest centered on the proposed placement location. Full point clouds of the objects to be placed, along with the cropped regions of the placement locations, are then fed into our low-level pose prediction model to output precise relative transformations for object placement.
Real Robot Experiments
For real robot experiments, we train our models using our fully synthetic dataset and test them directly in real-world scenarios in a zero-shot manner. The results show that our model can accurately predict placement poses for various configurations and objects, demonstrating the robustness and generalization capabilities of our proposed method.
Lid on Pot, Pot on Stove:
Plate on Rack:
Peg in Hole:
Stacking Rings:
Bottle on Cabinet:
Cup on Rack:
Vial in Vial Plate:
BibTeX
@misc{zhao2025anyplacelearninggeneralizedobject,
title={AnyPlace: Learning Generalized Object Placement for Robot Manipulation},
author={Yuchi Zhao and Miroslav Bogdanovic and Chengyuan Luo and Steven Tohme and Kourosh Darvish and Alán Aspuru-Guzik and Florian Shkurti and Animesh Garg},
year={2025},
eprint={2502.04531},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2502.04531},
}